
お久しぶりです。RPA事業部です。
今回は、Pythonで楽天市場APIを使用して各ジャンルのランキング情報取得作業を自動化してみましたので、コードを交えて紹介していこうと思います。
楽天APIを使えば、こんなことができるんだなーと、少しでも参考になれば幸いです。
事前準備
楽天APIを使用するためには、楽天会員への登録とアプリIDを発行する必要があります。
まだお済みでない方は、以下のリンクの「アプリID発行」から登録・発行して頂ければと思います。
https://webservice.rakuten.co.jp/
内容紹介
やりたいこと
やりたいことは以下になります。
・楽天が提供する「楽天市場商品検索API」を利用してすべてのジャンル(各子ジャンルごと)のランキングとその商品情報を取得
・取得した情報を以下のような形式でエクセルファイルとして保存
Book名:レディースファッション(親ジャンル名).xlsx
┗Sheet名:シャツ(子ジャンル名)
┗Sheet名:ワンピース(子ジャンル名)フォルダ構成
フォルダ構成は以下になります。
「output」というフォルダの中にエクセルファイルが保存されていきます。
※「rakutenichiba_genre.json」は「get_genreId.py」を起動後に作成されます。
.
┗output
┗config.py
┗create_ranking_file.py
┗get_genreId.py
┗rakutenichiba_genre.jsonコード紹介
コード内容を大まかに説明していきます。
まずは、confiy.pyです。取得したアプリIDを記載しています。
複数のモジュールから呼び出したいため作成しています。
'''
api使用に必要な下記要素をそれぞれ記述してください
・アプリID/デベロッパーID
・application_secret
・アフィリエイトID
'''
CLIENT_ME = {
'APPLICATION_ID':'',
'APPLICATION_SECRET':'',
'AFF_ID':''
}ジャンル情報取得について
初回はランキングを取得するのに必要なジャンルIDなどのジャンル情報がないため、楽天市場で取り扱っている商品のレベル2までのすべてのジャンル情報を取得していきます。
取得後はjson形式で保存して、使いまわせるようにしています。
コードは以下になります。
import datetime
import requests
import time
import json
from config import CLIENT_ME
req_url = 'https://app.rakuten.co.jp/services/api/IchibaGenre/Search/20140222'
genre_params = {
'applicationId':CLIENT_ME['APPLICATION_ID'],
'format':'json',
'formatVersion':'2',
'genreId':''
}
sta_time = datetime.datetime.today()
def get_genreId():
print("ジャンル取得中...")
cnt_p = 0
cnt_c = 0
##親ジャンル取得
res = requests.get(req_url,params=genre_params)
p_items = json.loads(res.text)
time.sleep(1)
dict_p_genre = {}
for p_genre in p_items['children']:
##子ジャンル取得
genre_params['genreId'] = p_genre['genreId']
res = requests.get(req_url,params=genre_params)
c_items = json.loads(res.text)
time.sleep(1)
##キー:子ジャンルID, 値:子ジャンル名・階層となる子ジャンル辞書作成
dict_c_genre = {}
for c_genre in c_items['children']:
dict_c_info = {
'genre_name':c_genre['genreName'],
'genre_level':c_genre['genreLevel']
}
dict_c_genre[c_genre['genreId']] = dict_c_info
cnt_c += 1
##キー:親ジャンルID,値:親ジャンル名・階層・子ジャンル辞書となる親ジャンル辞書作成
dict_p_info = {
'genre_name':p_genre['genreName'],
'genre_level':p_genre['genreLevel'],
'children':dict_c_genre
}
dict_p_genre[p_genre['genreId']] = dict_p_info
cnt_p += 1
##json形式で本ファイルの直下に保存
path = r'.\rakutenichiba_genre.json'
with open(path,encoding='utf-8',mode='w') as f:
json.dump(dict_p_genre,f,ensure_ascii=False,indent=2)
fin_time = datetime.datetime.today()
p_time = fin_time - sta_time
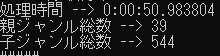
print(f"処理時間 --> {p_time}")
print(f"親ジャンル総数 --> {cnt_p}")
print(f"子ジャンル総数 --> {cnt_c}")
if __name__ == '__main__':
get_genreId()大まかな処理の流れは以下になります。
1.リクエストを送り、jsonで取得
2.取得した情報から必要な情報を用意した辞書へ格納
3.辞書をjson形式で本ファイルの直下に保存
ジャンル情報も楽天API(楽天市場ジャンル検索API)を使用して、取得しています。
また、取得したジャンル情報は使いまわしたいので、json形式で保存しています。
最後に処理時間とジャンル総数を出力しています。
なお、こちらのjsonは親ジャンルをキーとした辞書で各子ジャンルの情報を取り出すことができるようにしています。(辞書が入れ子で、少し複雑になってしまいました…他にもっと良い方法があると思いますが、お許しください)
結果は以下のようになりました。(jsonの方は長いため、一部のみ表示しております。)
{
"100371": {
"genre_name": "レディースファッション",
"genre_level": 1,
"children": {
"110729": {
"genre_name": "ワンピース",
"genre_level": 2
},
"568650": {
"genre_name": "シャツワンピース",
"genre_level": 2
},
・
・
・ランキング情報取得
ランキング情報取得するコードは以下になります。
import pandas as pd
import os,re,json,datetime,requests,\
openpyxl,time
from config import CLIENT_ME
import get_genreId
REQ_URL = 'https://app.rakuten.co.jp/'\
'services/api/IchibaItem/Ranking/20170628'
PATH_GENRE = r'.\rakutenichiba_genre.json'
PATH_OUTPUT = '.\output'
RE_PATTRN_CHACK_NAME = r'(:|\\|\?|\[|\]|\/|\*)'
WANT_ITEMS = [
'genreId','rank','itemCode',
'itemName','itemPrice','catchcopy',
'itemCaption','reviewAverage','reviewCount',
'shopCode','shopName','itemUrl','shopUrl'
]
sta_time = datetime.datetime.today()
this_date = format(sta_time,'%Y%m%d')
path_output_dir = f'.\output\{this_date}'
req_params = {
'applicationId':CLIENT_ME['APPLICATION_ID'],
'format':'json',
'formatVersion':'2',
'genreId':'',
'page':'1'
}
def main():
###必要ファイル用意
##指定名のjsonファイルがない場合は生成
if not os.path.isfile(PATH_GENRE):
print("#####ジャンル取得を行います#####")
get_genreId.get_genreId()
with open(PATH_GENRE,encoding='utf-8',mode='r') as f:
dict_genre = json.load(f)
if not os.path.isdir(PATH_OUTPUT):
os.mkdir(PATH_OUTPUT)
if not os.path.isdir(path_output_dir):
os.mkdir(path_output_dir)
##シート名に使用できない文字を一致させる正規表現
re_check_name = re.compile(RE_PATTRN_CHACK_NAME)
for p_genre_id,p_genre_info in dict_genre.items():
print(f'#####\n親ジャンルID --> {p_genre_id}')
print(f"親ジャンル名 --> {p_genre_info['genre_name']}\n#####")
#ランキングファイル作成
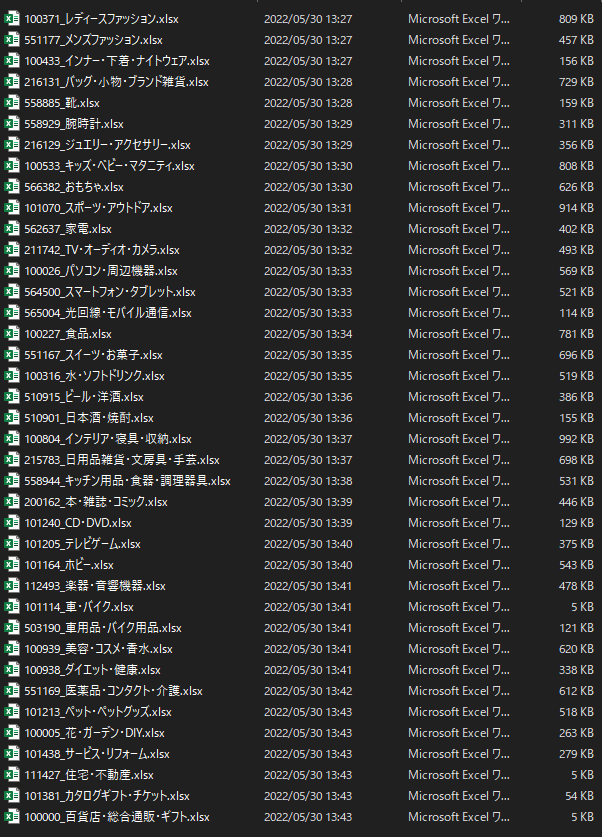
path_output_file = f"{path_output_dir}\{p_genre_id}_{p_genre_info['genre_name']}.xlsx"
wb = openpyxl.Workbook()
wb.save(path_output_file)
#各種ランキング情報取得
for c_genre_id,c_genre_info in p_genre_info['children'].items():
print(f"子ジャンルID --> {c_genre_id}")
print(f"子ジャンル情報 --> {c_genre_info}")
req_params['genreId'] = c_genre_id
res = requests.get(REQ_URL,params=req_params)
time.sleep(1)
if res.status_code != 200:
print(f"error --> {res.status_code}")
else:
#レスポンスをdf化
res = json.loads(res.text)
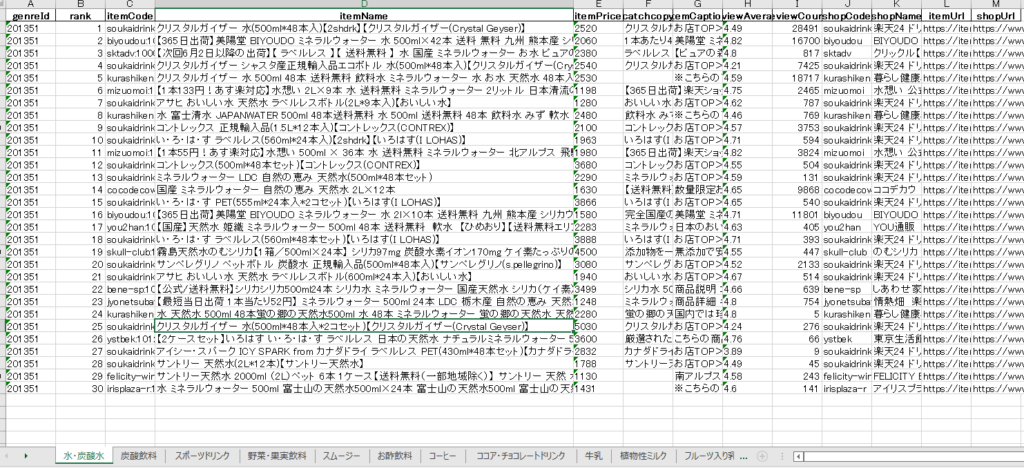
df = pd.DataFrame(res['Items'])[WANT_ITEMS]
#dfをシートへ出力
tmp_genre = is_suitble_sheet_name(re_check_name,c_genre_info['genre_name'])
with pd.ExcelWriter(path_output_file, mode='a') as writer:
df.to_excel(writer, sheet_name=tmp_genre,index=False)
#初期シート削除
wb = openpyxl.load_workbook(path_output_file)
ws = wb.worksheets[0]
if len(wb.worksheets) != 1:
wb.remove(ws)
else:
ws.title = '取得失敗'
ws['A1'] = '取得失敗'
wb.save(path_output_file)
fin_time = datetime.datetime.today()
p_time = fin_time - sta_time
print(f"処理時間 --> {p_time}")
##シート名に不適切な文字が含まれるまたは不適切な文字列の場合、編集する関数
def is_suitble_sheet_name(arg_re,arg_genre):
#文字判定(不適切文字はアンダーバーに置き換え)
match_result = arg_re.findall(arg_genre)
if match_result:
arg_genre = arg_re.sub('_',arg_genre)
#文字数判定
if len(arg_genre) >= 31:
arg_genre = arg_genre[0:31]
return arg_genre
if __name__ == '__main__':
print("#####\n処理を開始します\n#####")
main()
print("#####\n処理を終了します\n#####")ではざっくりと紹介していきます。
ランキング情報は「楽天市場ランキングAPI」を使用して、取得しています。
大まかな処理の流れとしては、リクエストを送り、jsonでランキング情報を取得します。そして取得した情報を何らかの形式に変換・保存という内容になります。処理の流れはジャンル取得とあまり変わりません。
12行目以降の「WANT_ITEM」というリストで、欲しい情報を定義しています。出力される情報はもっと多いですが、必要そうな情報だけDataFrameへ格納しエクセルへ出力しています。
もし、全ての情報が欲しい際は、76行目のDataFrameを作成する処理で「[WANT_ITEM]」を削除して頂ければと思います。
45行目までは出力するにあたり必要なフォルダを作成しています。
ジャンル情報があるjsonファイルがない場合は、上述のジャンル情報取得モジュールを呼び出し、作成するようにしています。
50行目以降は多重ループで各子ジャンルのランキング情報の取得、ファイル作成、出力、ファイル保存を行っています。
なお、シート名には文字列や使用文字に条件があるため、条件を満たさない場合は正規表現などを使用し、編集するようにしています。
全ての処理が終われば、楽天市場における全カテゴリでのランキング情報を取得ができ、エクセルで確認ができるようになります。
最後に、こちらも処理時間を出力しています。
結果は以下のようになりました。
20分程度で終了しました。
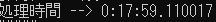
さいごに
いかがだったでしょうか?
今回は楽天APIとPythonを使用して、ジャンル情報を取得およびランキング情報取得作業を自動化する内容でした。
楽天APIは他にもいくつかあるので、次の自動化ツール作成を企画しています。
また、TwitterやそのほかのSNSのAPIを合わせて使用し、取得した商品情報を自動ツイート・チャットなども面白いかもしれません。
完成したらまた紹介したいと思います。
なお、弊社ではこのように業務改善の一環として自動化に関するソリューションを提供しています。
「こんな作業を自動化したい・できるのか?」等、業務効率化に関するご相談があれば、お問い合わせからお気軽にご連絡下さい。